베이지안 A/B는 "p-value < 0.05"가 아니라 "B가 A보다 좋을 확률 0.92"를 줍니다. 그 확률이 정직하려면 prior를 잘 잡아야 하고, HDI를 잘못 읽으면 함정이 옵니다. 마케터 시선에서 prior·posterior·HDI 정리.
"B안이 A보다 좋을 확률 92%"라는 한 줄이 회의를 한 번에 정리합니다. 베이지안 A/B의 매력입니다. 그런데 그 92%라는 숫자가 정직하려면 prior를 어떻게 잡았는지, HDI를 어떻게 해석했는지가 함께 따라와야 합니다. 이 글은 마케터 시선에서 베이지안 A/B의 prior 설계, posterior 해석, HDI의 함정을 정리합니다.
마케터가 이 글을 읽어야 하는 이유: 빈도주의 A/B의 "p-value < 0.05"는 실무에서 늘 어색합니다. "그래서 B가 더 좋다는 거야 아니야?" 베이지안은 그 질문에 직접 답합니다. 다만 prior를 무심코 잡으면 답이 흔들리고, HDI를 단순 신뢰구간처럼 읽으면 의미가 깨집니다. 두 가지만 잘 잡으면 회의에서 의사결정 속도가 한 단계 올라갑니다.
1. 빈도주의 A/B와 베이지안 A/B의 한 줄 차이
| 항목 | 빈도주의 | 베이지안 |
|---|---|---|
| 답하는 질문 | "이 차이가 우연일 확률은?" | "B가 A보다 좋을 확률은?" |
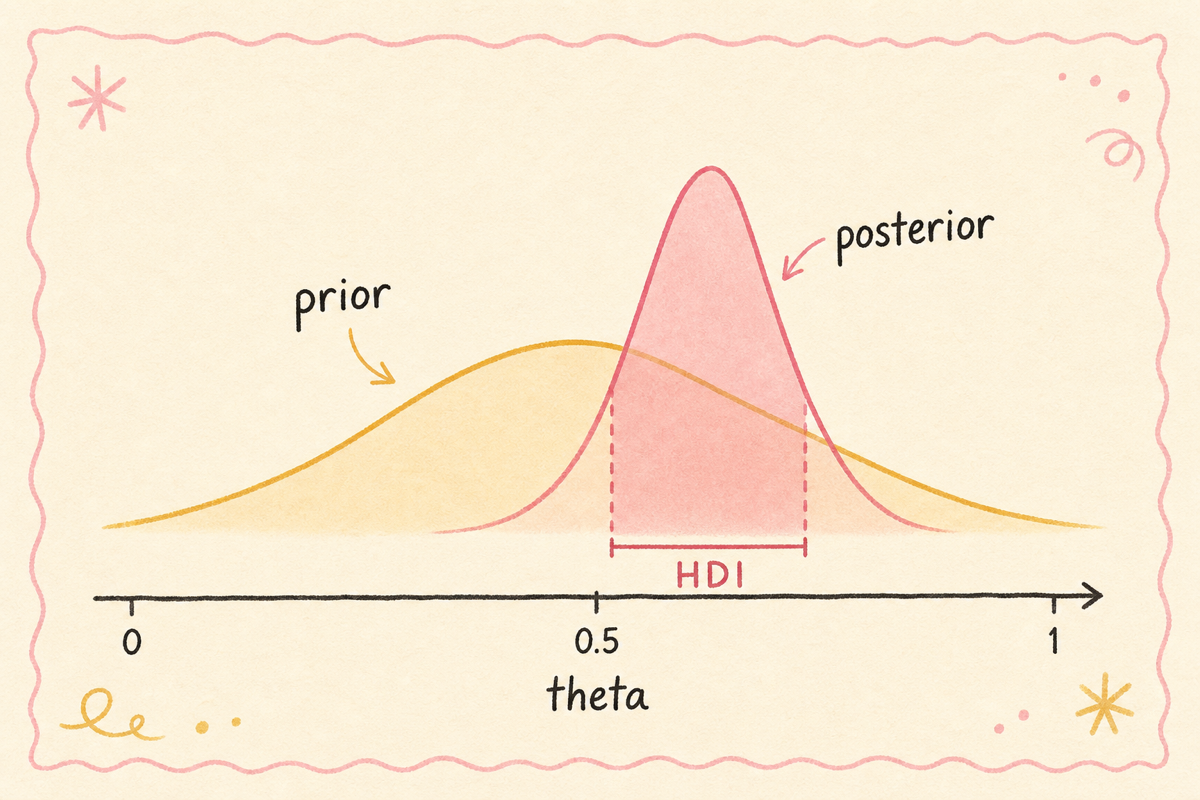
| 출력 | p-value, 신뢰구간 | posterior 분포, HDI |
| 해석 | "기각/채택" 이분법 | "어느 정도 더 좋은가" 연속적 |
| 표본 부족 자리 | 검출력 부족 | prior가 정보 보강 |
| 회의 친화도 | 낮음 (해석 어려움) | 높음 (확률로 직접 답) |
베이지안의 직관: 사전 믿음(prior)을 데이터로 갱신해 사후 믿음(posterior)을 만든다. posterior가 의사결정의 입력이 됩니다.
2. Prior 잡는 법 — 세 가지 표준 패턴
prior는 "데이터를 보기 전에 우리가 알고 있던 것"입니다. 마케팅 자리에 자주 등장하는 세 패턴을 보겠습니다.
2-1. 무정보 prior — 정보 없을 때
Beta(1, 1) (= 균등분포)는 "0과 1 사이 어디든 가능성 동일"을 의미합니다. 정보가 전혀 없을 때 안전한 출발점.
장점: 사전 편향 없음. 단점: 표본 작을 때 posterior가 흔들리기 쉬움.
2-2. 약한 정보 prior — 일반 상식 반영
Beta(2, 8)은 "전환율이 낮은 자리(평균 약 20%)에 약한 사전 정보". 마케터가 "이 캠페인은 전환율이 보통 15-25% 사이"라는 상식이 있을 때 그 상식을 prior에 반영.
이런 prior는 데이터가 적을 때도 합리적인 posterior를 만들고, 데이터가 많아지면 prior 영향이 사라져 데이터가 답을 결정합니다.
2-3. 강한 정보 prior — 과거 데이터 활용
같은 캠페인의 작년 분기 데이터가 있으면, 그 데이터를 prior로 사용. 작년 분기에 1000명 중 250명 전환이라면 Beta(250, 750)을 prior로 잡습니다. 이게 베이지안 A/B의 가장 강력한 자리 — 과거 데이터가 사전 정보로 그대로 들어옵니다.
이번 분기 작은 표본만으로도 posterior가 안정적으로 추정됩니다.
| Prior 종류 | 표현 | |
|---|---|---|
| 무정보 | 1, 1 | "아는 게 없음" |
| 약한 정보 | 2, 8 | "전환율 약 20% 가정" |
| 강한 정보 | 250, 750 | "작년 데이터로 신뢰" |
3. Posterior — 데이터로 갱신된 사후 분포
prior에 데이터가 들어가 posterior가 됩니다. Beta-Binomial 결합의 표준 결과:
는 성공 수(전환), 는 실패 수(비전환). 1000명 노출 250명 전환이라면 . prior가 Beta(2, 8)이라면 posterior는 Beta(252, 758). 마케터 직관: 사전에 가정한 알파·베타에 실제 관측치를 더한다. 데이터가 많을수록 prior 영향은 사라지고 posterior가 데이터에 수렴.
A/B 두 변형 모두에 같은 절차를 적용해 두 posterior , 를 얻습니다. 비교는 두 분포의 비교입니다.
4. "B가 A보다 좋을 확률" 계산
두 posterior에서 직접 샘플링해 비교합니다.
P(B > A) = posterior 샘플 중 B 샘플이 A 샘플보다 큰 비율
10000개 샘플을 두 분포에서 각각 뽑아 짝지어 비교한 비율이 그 확률. 92%면 "B가 A보다 좋을 확률 92%"라고 회의에서 한 줄로 답할 수 있음.
이게 빈도주의 p-value가 못 답하는 자리입니다. p-value는 "차이가 우연일 확률"이지 "B가 A보다 좋을 확률"이 아닙니다. 둘은 다른 질문입니다.
5. 코드 한 묶음 — Beta-Binomial Bayesian A/B
이게 글에 박는 유일한 코드입니다.