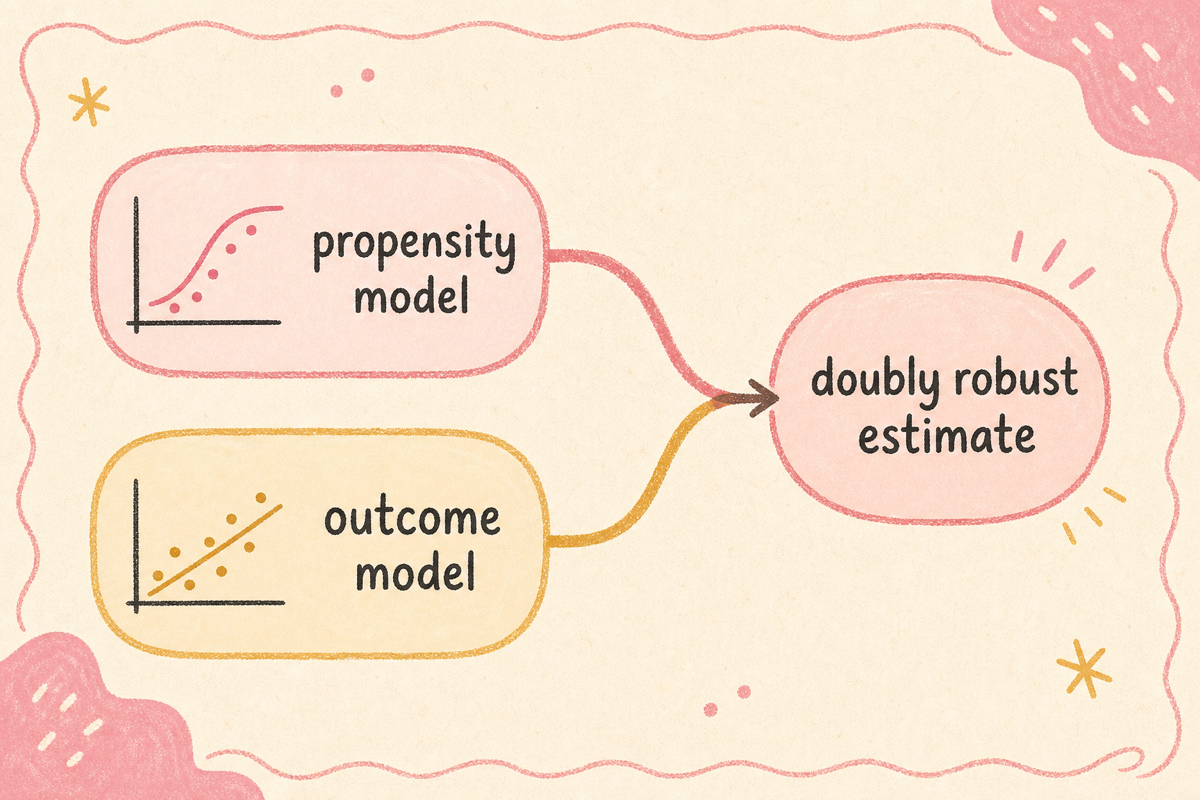
PSM·IPW는 propensity 모델이 틀리면 무너지고, 회귀는 outcome 모델이 틀리면 무너집니다. doubly robust는 두 모델을 결합해 둘 중 하나만 맞으면 정직한 효과 추정. 마케팅 인과 분석의 안전판.
무작위 배정이 안 되는 자리에 인과 효과를 추정하려면 두 가지 길이 있습니다 — propensity 모델 기반(PSM·IPW) 또는 outcome 모델 기반(회귀). 두 길은 각각 서로 다른 자리에서 깨집니다. doubly robust(이중 안전) 추정은 두 모델을 결합해, 둘 중 하나만 맞으면 정직한 효과 추정을 보장합니다. 마케팅 인과 분석의 안전판.
마케터가 이 글을 읽어야 하는 이유: 인과 분석 결과를 회의에서 신뢰성 있게 보고하려면 "이 추정의 모델 가정 중 어느 게 깨져도 결과가 무너지는가"를 먼저 답해야 합니다. doubly robust는 그 답이 "둘 다 깨져야 무너진다"라 회의 신뢰도가 한 단계 올라갑니다.
1. PSM·IPW가 흔들리는 자리
PSM이나 IPW(역확률 가중)는 propensity score 를 정확히 추정한다는 가정에 의존합니다.
propensity 모델이 틀리면 매칭·가중이 잘못되고 효과 추정이 편향됩니다.
흔한 자리:
- 비선형 관계 (로지스틱이 아닌 GBM 필요)
- 변수가 너무 많음 (overfitting)
- 관측 변수 부족 (unmeasured confounder)
2. Outcome 회귀가 흔들리는 자리
다른 길은 outcome을 직접 모델링하는 것. 를 회귀로 추정하고, 과 의 차이를 효과로.
outcome 모델이 틀리면 회귀 계수가 편향되고 효과 추정도 무너집니다.
흔한 자리:
- 비선형 outcome (회귀 가정 위반)
- interaction 효과 미포함
- 결과 변수의 분포 가정 위반
3. Doubly robust의 한 줄 직관
두 모델을 결합해 어느 하나만 맞으면 정직한 추정을 보장.
둘 다 잘 추정하면 효율 최고, 하나만 맞아도 unbias, 둘 다 틀리면 무너짐.
수식으로(AIPW = Augmented IPW):
- 첫 두 항: IPW 보정 (residual에 가중)
- 세 번째 항: outcome 모델의 직접 추정
핵심: propensity 모델이 정확하면 첫 두 항이 정직. outcome 모델이 정확하면 세 번째 항이 정직. 둘 다 틀려야 무너짐.
4. AIPW vs 단순 IPW·회귀 비교
같은 데이터에 세 추정량을 적용하면 어떻게 다른지.
| 추정량 | propensity 정확 | outcome 정확 | 결과 |
|---|---|---|---|
| IPW | ✓ | ✗ | 정직 |
| 회귀 | ✗ | ✓ | 정직 |
| IPW | ✗ | ✗ | 편향 |
| 회귀 | ✗ | ✗ | 편향 |
| AIPW | ✓ | ✗ | 정직 |
| AIPW | ✗ | ✓ | 정직 |
| AIPW | ✗ | ✗ | 편향 |
AIPW가 IPW와 회귀의 위험 분산. 한 모델이 흔들려도 다른 모델이 받쳐주는 구조.
5. 코드 한 묶음 — Python AIPW 구현
이게 글에 박는 유일한 코드입니다.